
公司动态首页 > 新闻动态 > 公司动态
肿瘤、炎症、自身免疫性疾病等多种疾病中,体内产生和累积大量的自身抗体。自身抗体产生的机制目前尚不完全明确,主流的理论假说是免疫监视理论 (immune surveillance),如图1所示。肿瘤在发生过程中受到免疫系统的攻击,诱导T细胞主导的细胞免疫和B细胞主导的体液免疫。能够引起机体产生免疫反应的抗原包括异常高表达、突变、错误折叠、错误定位以及修饰异常等的蛋白[1],蛋白的来源包括核蛋白、细胞质蛋白等, 蛋白的种类涉及细胞周期蛋白、RNA结合蛋白以及生长因子等[2,3]。
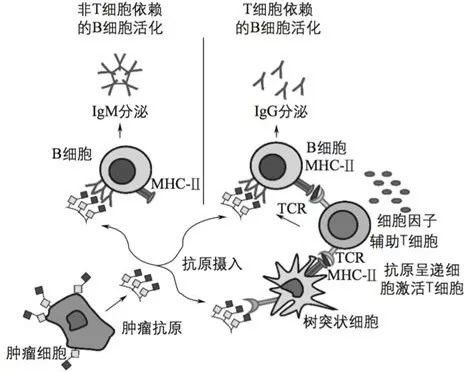
图1. 肿瘤自身抗体产生的过程
自身抗体(TAAs)用于肿瘤早期诊断的价值已获得广泛认可,在多种类型的肿瘤中已经发现多个TAAs,并且有诸多综述文献对肿瘤(如肝癌[4]、肺癌[5]、食管癌[6]、结直肠癌[7]等)的TAAs进行了全面的总结和分类,代表性的TAAs包括p53、c-myc等抑癌基因蛋白或驱动基因蛋白、MAGE-A蛋白家族、NY-ESO-1等CT抗原(cancer-testis antigen)以及其他多种类型的蛋白。
作为早期诊断的一类指标,自身抗体有几个特点:
1) 伴随肿瘤的发生过程产生先于临床症状;
2) 自身抗体可使用经典的ELISA方法通量检测,同时抗体相比于蛋白在血液中更稳定;
3) 疾病个体多样性和复杂性,虽然对于一个特定的自身抗体,灵敏度可能比较低,但可以通过建立一个标志物组合,联合多个自身抗体进行验证;而肿瘤自身抗体研究依赖于抗原,传统的方法已不能满足全局性的筛查和大规模样本验证。蛋白质芯片特别是包含有约20,000个重组人蛋白的HuProtTM 芯片提供了高效的方式,可进行大量样本的快速筛选和验证。
HuProtTM人类蛋白质组芯片是目前国际上通量最高的蛋白质芯片(通量第二的是thermo fisher的9000多个蛋白的芯片,2018年底停产),覆盖75%的人类基因组ORF区,重组蛋白采用酵母表达系统,进行表达与纯化鉴定。在芯片上每个蛋白质均设置技术重复,并设有多种质控点,确保实验体系稳定可靠。
该芯片贡献了Cell、Nature、Science等近百篇文献:在基础科研领域适用于全局性地进行蛋白-蛋白互作[8]、蛋白-核酸互作[9]、蛋白-小分子互作[10]以及翻译后修饰研究[11];在临床研究中,系统性地发现肿瘤及免疫相关疾病的自身抗体,用于诊断标志物的发现[12-14]。
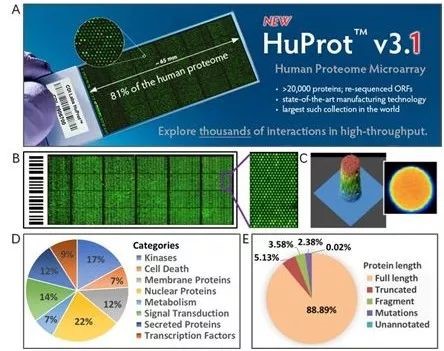
图2. HuProtTM人蛋白质组芯片蛋白种类及分布
首先,血清以一定稀释比例同封闭后的芯片进行孵育,并洗去未结合的抗体,再使用不同荧光标记的二抗同时检测IgG抗体亚型和IgM抗体亚型,然后通过荧光扫描仪读取各蛋白点的信号。
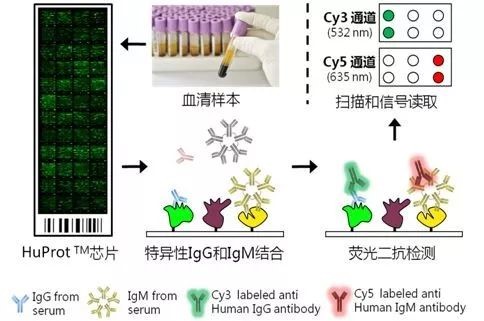
图3. 基于HuProtTM人蛋白质组芯片的血清标志物项目实验流程
![]() 实验设计方案(芯片部分)
实验设计方案(芯片部分) ![]()
第一步:HuProt™蛋白组芯片,初筛
使用涵盖~20,000个人类重组蛋白的HuProtTM ProteomeMicroarray进行初步筛选,以发现具有一定差异的潜在的自身抗原。实施具体方案:
样本设置: 疾病组15例,要求:典型的病例样本,明确的临床诊断结论,样本保存完好(-80 °C保存),完善的临床信息。健康对照组15 例,要求:整体的性别、年龄同疾病组匹配,样本保存完好。
数据分析: 按照以下标准确定候选标志物:p值<0.05;阳性率在疾病组显著高于健康对照组(按照cutoff值,健康组阳性率<10%,疾病组阳性率>30%);候选标志物个数选择约30个(按照优先级排序)。
第二步:定制蛋白芯片,大样品验证
通过筛选获得的候选自身抗原(约30个),构建定制小芯片(Focused Protein Array)进行大样品检测(1张芯片12个block)并获得所有响应数据。
样本设置: 疾病组100例,健康对照组100例,疾病和健康样本要求同上;
数据分析:随机选择100例(50疾病/50对照)样本进行模型训练(training),建立特异辨别模型。利用其余样本数据对训练模型的分辨能力进行验证(test),并通过ROC曲线评价模型的特异性和灵敏度。

图4. 芯片实验样本设计流程图
![]() 芯片整体服务项目
芯片整体服务项目 ![]()
蛋白质芯片具有高通量、可平行分析的特点,特别适合用于寻找各类与免疫相关疾病的血清标识物。2014年广州博翀生物科技有限公司正式成为美国CDI人类蛋白质芯片的中国区代理商,目前博翀生物已经可以提供基于蛋白质芯片的整体科研服务。而且公司正在推广肿瘤早期诊断自身抗体标志物筛选项目(TEAMS) http://www.bc-bio.com/cn/news_show.php?id=177和自身免疫疾病诊断自身抗体标志物筛选计划(ADREAM) http://www.bc-bio.com/cn/news_show.php?id=185。
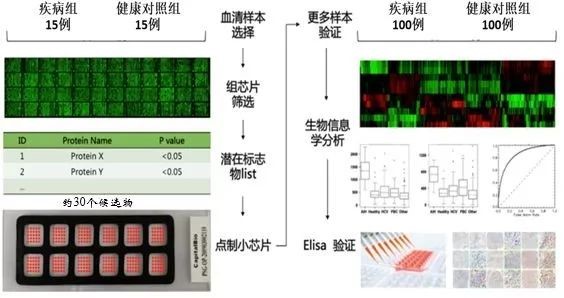
图5. 基于蛋白质芯片的整体服务
![]() HuProtTM芯片在发现肿瘤自身抗体标志物方面的独特优势
HuProtTM芯片在发现肿瘤自身抗体标志物方面的独特优势 ![]()
1) 蛋白质库较大,涵盖近80%的编码基因且89%的蛋白为全长蛋白,可保证抗原蛋白的三维构象。另外,高通量芯片使得检测过程异常简便,免去了抗原鉴定的复杂步骤,通过芯片扫描即可获取全部蛋白抗原的自身抗体信号。简便的过程使得系统误差较小,因此可保证实验的一致性。
2) 适用于大规模样本筛选。微型化的芯片可同时进行多个样本的并行分析,传统方法则很难同时进行多个样本的检测。一方面自身抗体存在较大个体差异,小样本量筛选或将样本混合以获得统计学结果必然降低筛选的成功率;另一方面,在研究同一病人不同时间点的一系列样本时,需要同时检测多个样本。
3) 所消耗的样本量较少。由于微型化,检测所有蛋白所需要的血清样本量仅为100 μL 以下,极大节省了宝贵的临床样品。
参考文献
[1] Casiano C, et al. Tumor- associated antigen arrays for the serological diagnosis ofcancer.Mol Cell proteomics, 2006, 5(10):1745-1759.
[2] Hanash S, et al. Emerging molecularbiomarkers-blood-based strategies to detect and monitor cancer. Nat Rev ClinOncol, 2011, 8(3):142-150.
[3] Desmetz C, et al. Autoantibody signatures:progressand perspectives for early cancer detection. J Cell MolMed, 2011, 15(10):2013-2024.
[4] Pan X, et al. Progress in studies onautoantibodies against tumor-associated antigens in hepatocellularcarcinoma.Transl Cancer Res,2016, 5(6):845-859.
[5] Broodman I, et al. Serum protein markers for theearly detection of lung cancer:a focus on autoantibodies. J ProteomeRes, 2017, 16(1):3-13.
[6] Zhang H, et al. Serum autoantibodies in the earlydetection of esophageal cancer:a systematic review. Tumour Biol, 2015, 36(1):95-109.
[7] Chen H, et al. Blood autoantibodies against tumor-associatedantigens as biomarkers in early detection of colorectal cancer. CancerLett, 2014, 346(2):178-187.
[8] Deng R P, et al. Global identification of O‐GlcNAc transferase (OGT)interactors by a human proteome microarray and the construction of an OGTinteractome. Proteomics, 2014, 14(9): 1020-1030.
[9] Fan B, et al. A human proteome microarray identifies that the heterogeneous nuclearribonucleoprotein K (hnRNP K) recognizes the 5' terminal sequence of thehepatitis C virus RNA. Mol Cell Proteomics, 2014, 13(1): 84-92.
[10] Zhang H, et al. Systematic identification of arsenic-binding proteins reveals thathexokinase-2 is inhibited by arsenic. PNAS, 2015: 201521316
[11] Zhaoshou Y, et al. A human proteome array approach to identifying key host proteinstargeted by Toxoplasma kinase ROP18. Mol Cell Proteomics, 2017, 16.
[12] Yang L, et al. Identification of serum biomarkers for gastric cancer diagnosis using ahuman proteome microarray. Mol Cell Proteomics, 2015.
[13] Hu C J, et al. Identification of new autoantigens for using human proteome microarrays. Mol Cell Proteomics, 2012, 11(9):669-680.
[14] Hu C J, et al. Identification of novel biomarkers for Behcet Disease diagnosis usingHuProt array approach. Mol Cell Proteomics, 2017, 16(2): 147-156.

